실제 데이터로 머신러닝 모델 만들기 : 1
안녕하세요. 빅데이터분석기사 취득 이후에, 실제 데이터를 가지고 꼭 한번 분석하는 시간을 가져야겠다는 생각을 했었는데요. 시중에 나와있는 머신러닝 모델을 학습시키기에 최적화된 데이
hiimgood.tistory.com
이전 글에 이어서 포스팅합니다.
3. 분류모형
이전 글에서 말씀드렸던 것처럼 회귀모형으로 예측하기에는 데이터의 구조가 특이한 부분이 었어 어렵고 분류 모델로 학습하는 것이 조금 더 효율적이면서 과제의 기존 목적도 어느 정도 달성할 수 있는 방법이라고 생각하였습니다.
균이 검출되지 않은 것 : 0
균이 검출된 것 : 1
로 다시 라벨링하여 데이터의 분포를 확인하였습니다.
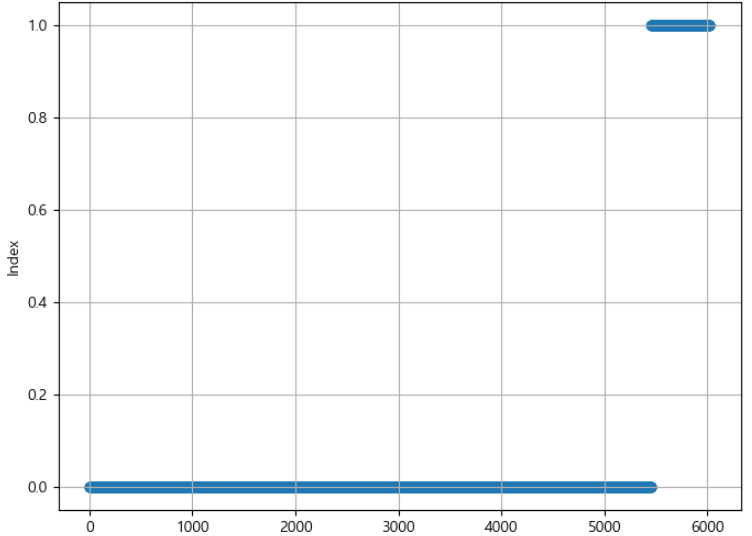
이렇게 보니 확연하게 불균형 데이터라는 것을 볼 수 있었습니다. counter 사용하여 실제 얼마나 불균형한지 확인한 결과 {0: 4354, 1: 464} 로 약 10 : 1 정도의 비율로 이 데이터를 그대로 사용하면 불균형 데이터의 전형적인 문제점인 과적합과 낮은 f1 score 등의 문제가 있을 것으로 예상되었습니다. 그럼에도 기존 데이터로 한번 그대로 모형 학습을 수행해서 성능을 확인하였습니다.
def get_scores(model, x_train, x_valid, y_train, y_valid):
A = model.score(x_train, y_train)
B = model.score(x_valid, y_valid)
pred1 = model.predict_proba(x_valid)[:, 1]
C = roc_auc_score(y_valid, pred1)
pred2 = model.predict(x_valid)
D = f1_score(y_valid, pred2)
return f'ACC : {A: .4f} {B: .4f} , ROC : {C: .4f}, F1 : {D: .4f}'
model1 = RandomForestClassifier()
model1.fit(X_train, y_train)
pred1 = model1.predict(X_test)
model2 = DecisionTreeClassifier()
model2.fit(X_train, y_train)
pred1 = model2.predict(X_test)
print(get_scores(model1, X_train, X_test, y_train, y_test))
print(get_scores(model2, X_train, X_test, y_train, y_test))
ACC : 1.0000 0.9037 , ROC : 0.7634, F1 : 0.0645
ACC : 1.0000 0.8589 , ROC : 0.6006, F1 : 0.2609
이번에도 하이퍼파라미터를 아무것도 조정하지 않고 RF, Decisiontree 두개의 모델로 학습시킨 결과
위에서 예상했던 대로 과적합이 심하고, f1 score 가 너무나도 낮은 것을 볼 수 있었습니다.
그래서 데이터를 oversampling 하기로 했습니다.
Data augmentation in microbiome data (데이터 불균형)
마이크로바이옴 데이터에 머신러닝 기법을 적용해보려 할 때 가장 먼저 생각나는 것은 Bacteroides, Prevotella, Ruminococcaceae 분류이다. (이하 B, P, R) 위의 3개의 gut microbiota phenotype 중에서 탄수화물 위
hiimgood.tistory.com
예전에 불균형 데이터를 처리하는 것에 대한 논문을 리뷰한 적이 있었는데요, 어쩌다보니 여기서 바로 써먹을 수 있었습니다. 상당히 타이밍이 좋았네요.
from collections import Counter
from imblearn.over_sampling import SMOTE
print('Original dataset shape %s' % Counter(y_train))
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X_train, y_train)
print('Resampled dataset shape %s' % Counter(y_res))
#Original dataset shape Counter({0: 4354, 1: 464})
#Resampled dataset shape Counter({0: 4354, 1: 4354})
undersampling, oversampling 등 고려해볼만한 것이 몇 가지 있지만 아무래도 oversampling 을 사용하고자 했고 SMOTE, ADASYN, borderline SMOTE 등의 알고리즘을 모두 한번 수행해보았습니다.
위의 코드는 SMOTE 를 수행한 결과이고 10:1 정도의 불균형했던 데이터를 동일한 수로 맞춘 뒤 다시 모델에 학습시켰습니다.
model1 = RandomForestClassifier()
model1.fit(X_res, y_res)
pred1 = model1.predict(X_res)
model2 = DecisionTreeClassifier()
model2.fit(X_res, y_res)
pred1 = model2.predict(X_res)
print(get_scores(model1, X_res, X_test, y_res, y_test))
print(get_scores(model2, X_res, X_test, y_res, y_test))
#ACC : 1.0000 0.8963 , ROC : 0.7493, F1 : 0.1830
#ACC : 1.0000 0.8680 , ROC : 0.6187, F1 : 0.2933
생각보다 드라마틱한 변화는 없지만 f1 score 가 증가하는 경향은 확인했습니다.
from collections import Counter
from imblearn.over_sampling import ADASYN
print('Original dataset shape %s' % Counter(y_train))
ad = ADASYN(random_state=42)
X_res, y_res = ad.fit_resample(X_train, y_train)
print('Resampled dataset shape %s' % Counter(y_res))
model1 = RandomForestClassifier()
model1.fit(X_res, y_res)
pred1 = model1.predict(X_res)
model2 = DecisionTreeClassifier()
model2.fit(X_res, y_res)
pred1 = model2.predict(X_res)
print(get_scores(model1, X_res, X_test, y_res, y_test))
print(get_scores(model2, X_res, X_test, y_res, y_test))
#ACC : 1.0000 0.9029 , ROC : 0.7435, F1 : 0.2353
#ACC : 1.0000 0.8490 , ROC : 0.5821, F1 : 0.2288ADASYN 은 생각보다 별로네요. 물론, 더 많은 모델을 사용하거나 하이퍼파라미터를 조정하여서 개선할 여지는 있습니다. 그런 것들은 나중에 gridsearchCV 같은 것으로 한번 해볼 생각입니다.
이외에 borderlineSMOTE, SVMSMOTE 같은 것들도 해봤지만 기본 SMOTE 가 가장 f1 score 를 많이 향상시켰습니다.
4. 중간점검
일단 oversampling 만으로는 좋은 모델을 만들기 어려울 것 같습니다. f1 score 가 조금씩은 올라가는 부분이 있는데 과적합이 심한 것을 확인하였기 때문에 데이터 전처리로 다시 돌아갈 생각입니다.
사실 머신러닝 학습을 염두에 두고 수집한 데이터가 아니어서 y 값을 예측하기 좋은 feature 가 많지는 않았고 특히, 지명에 관한 feature 가 라벨링이 연차에 따라 조금씩 상이한 부분이 있어서 이 부분을 잘 처리하면 과적합 문제는 많이 사라질 것이라고 생각합니다.
지금 생각하고 있는 것은 지명에 대해 위도, 경도 파생변수를 만들어서 그것들을 예측에 사용하는 것이 어떨까 하는데 현실적으로 가능한 것인지는 모르겠습니다. 샘플을 채취한 정확한 위치를 알기가 어려워서 어느 정도는 타협이 필요할 것 같기도 합니다.
이 부분에 대해 계속 고민해보면서 진행이 되는 부분이 있으면 다시 포스팅하러 오겠습니다.
'[머신러닝]' 카테고리의 다른 글
| [머신러닝] 모델에 학습시키기 위한 마이크로바이옴 데이터의 형식 (0) | 2023.11.29 |
|---|---|
| [머신러닝] CNN 을 사용한 마이크로바이옴 데이터의 분류 (T2D vs healthy) (1) | 2023.11.26 |
| 실제 데이터로 머신러닝 모델 만들기 : 1 (0) | 2023.09.16 |
| microbiome data 에서 explainable AI 의 사용 (SHAP) (0) | 2023.09.04 |
| 제 6회 빅데이터분석기사 자격증 취득 후기 (0) | 2023.08.24 |