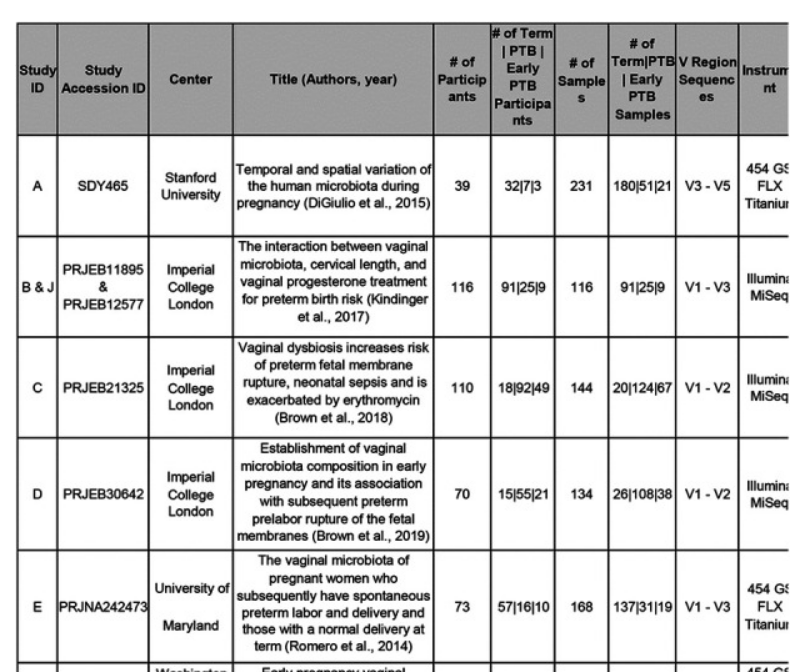
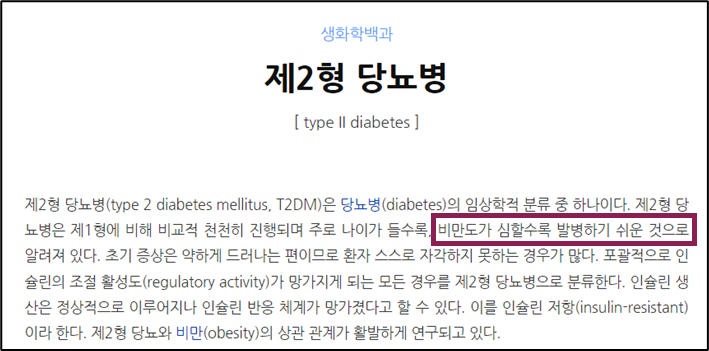
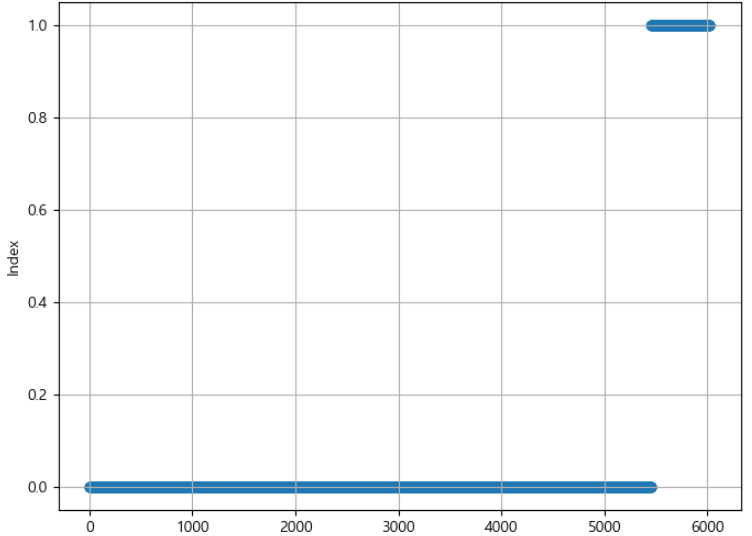
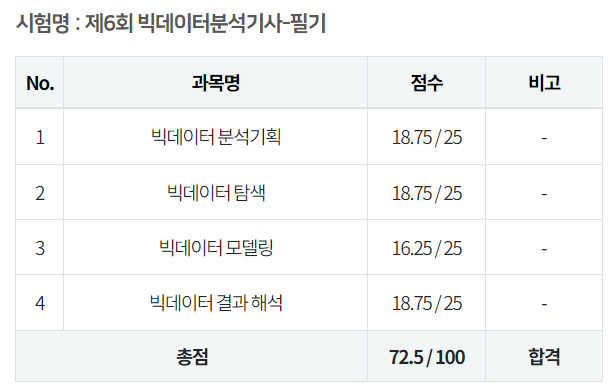
요즘 기계학습의 성능이 얼마나 올라왔는지 chatgpt 를 보면 체감이 되는 부분이 있습니다. 4.0 버전이 성능이 정말 좋고 특히 코딩이 필요할 때 전공자가 아닌 입장에서 시간을 꽤나 절약할 수 있게 해 주고 이런 흐름은 나중에는 코딩으로 단순히 데이터를 시각화하는 데에 그치는 것이 아니라 모델을 만들고 데이터를 학습시키는 것이 어렵지 않은 작업이 될 것이라고 생각합니다. 그래서 대용량의 유전체 데이터를 다루는 이쪽 분야에서도 움직임을 꾸준하게 쫓아보는 것도 이후에 많은 도움이 될 것이라 생각하고 있습니다. 이전에도 관련해서 포스팅을 올렸던적이 있었는데 일단 마이크로바이옴 데이터를 학습시키는 과정에서 가장 먼저 표준화되어야 하는 것은 어떻게 전처리해서 학습시킬 것인가라고 생각하고 있습니다. 물론 많은 ..