기본적으로 sampling depth 를 설정하기 위해서는 어느 정도의 타협이 필요한 것 같습니다.
1. 너무 많은 정보를 손실하지 않을 정도로 설정
2. 특정 샘플의 값이 튀어서 너무 낮다면 해당 샘플을 분석에 사용하지 않고 sampling depth 를 유지
NGS 데이터 분석하시는분들과 이야기해보면 그래도 sampling depth 가 10,000 은 넘어야 샘플 간에 비교하는 분석이 의미 있지 않나라고 이야기를 많이들 하십니다. 만약 전체적인 퀄리티가 10,000 보다 낮다면 샘플 퀄리티 또는 시퀀싱 퀄리티 상의 문제라고보고 혹은 몇 개 튀는 값들이 10,000 보다 낮다면 샘플을 몇 개 포기하고 이후 분석 진행하는 게 더 좋은 것 같다는 의견이 주류고 저도 그렇게 생각합니다.

그럼에도 실제 시퀀싱 데이터를 받아서 퀄리티를 확인해보면서 제가 느낀 것 중 하나가 NGS 특성상 여러 RUN 에 걸쳐서 샘플이 시퀀싱되는 경우가 많은데 일반적으로는 동일 업체에서 동일한 기기, 기술 사용해서 시퀀싱 수행하면 RUN 끼리 비슷한 퀄리티의 결과를 받아볼 수 있습니다.
그런데 RUN 이 너무 많은 경우에 가끔 한번씩 퀄리티가 튀거나, 어쩔 수 없이 다른 업체에 맡겨야 한다던지 등의 문제가 중간에 생기면 그 RUN에 속한 샘플 전체가 값이 튀어버리는 문제가 있었습니다.
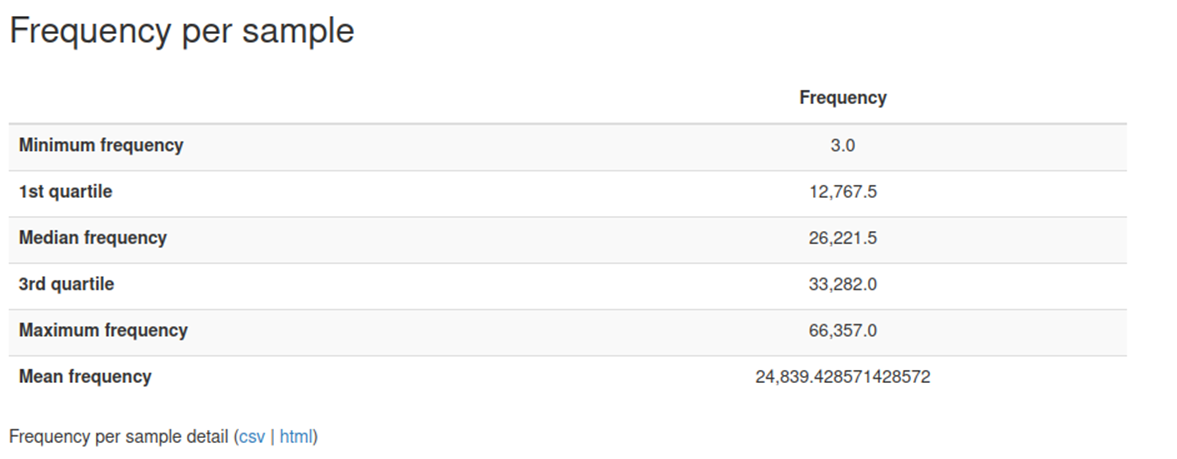
이번에 시퀀싱받은 데이터인데 많은 RUN 에 걸쳐 샘플이 퍼져있었어서 조금 값이 튀는 것을 볼 수 있습니다. 평균이 25,000 정도 되어서 평균적인 퀄리티는 좋은 편인데 1 사분위가 12,700 정도로 아래 그래프를 보시면 10,000 이하 값이 약 20개 정도 되는 것을 볼 수 있습니다.

그렇다면 이런 경우, 20 개정도 값을 제하고 분석을 진행하는게 나은지 아니면 10,000 밑에서 약 5,000 정도에서 끊어보는 게 나은지 잘 감이 안 오긴 합니다.
실제 10,000 밑의 값을 확인해보면 다음과 같습니다.
9876, 9690, 9656, 9506, 9481, 9276, 9038, 9029
8919, 8680, 8391, 8222, 8118, 8075
7737, 7663, 7363
6958, 6923, 6689, 6588, 6312
5446
4328
3752
그래서 해당 데이터 가지고 sampling depth 를 10,000, 5,000 으로 각각 rarefying 해서 rarefraction curve 를 확인해 봤습니다.


observed features metric 으로 alpha rarefaction 을 5,000 과 10,000 에 대해서 각각 확인해 본 결과 전체적인 기울기 자체가 5,000 일 때 조금 더 가파른 느낌이 있습니다. 그러나 눈에 띄는 차이가 보이지는 않아서 사실 어떤 것을 사용해도 크게 문제는 없을 것 같다고 생각했습니다. 그러면 샘플을 조금 더 많이 사용할 수 있는 5,000 으로 sampling depth 를 정해야겠죠.
위의 rarefaction curve 도 그렇고 여기저기 찾아본 결과 사실 심하게 극단적인 값만 아니라면 (e.g. 1,000, 2000) 최대한 샘플을 버리지 않는 방향으로 많이 선택하는 것 같습니다. 어쨌든 diversity 분석도 좋지만 taxa plot 분석에서 조금 더 직관적인 결과를 보여줄 수 있는 부분이 많은 것 같고 diversitiy 분석은 분석 결과의 대략적인 경향만 보여준다고 생각해서 여기에 많은 신경을 쓰기보다는 compositional data 를 다루는 부분에 대해서 더 많이 공부해야 할 것 같습니다.
아직 학생이라 잘 모르는 부분이 많습니다. 관련해서 많은 조언 부탁드립니다~
'bioinfo' 카테고리의 다른 글
| QIIME2 feature classifier : 1 (greengenes2 database) (1) | 2023.10.26 |
|---|---|
| Divisive Amplicon Denoisinig Algorithm (DADA2) output file (microbiome) (1) | 2023.10.21 |
| Sampling depth 와 rarefaction (microbiome) (2) | 2023.10.07 |
| Data augmentation in microbiome data (데이터 불균형) (0) | 2023.09.06 |
| Sequencing quality (Illumina Miseq) : 3 (0) | 2023.09.03 |