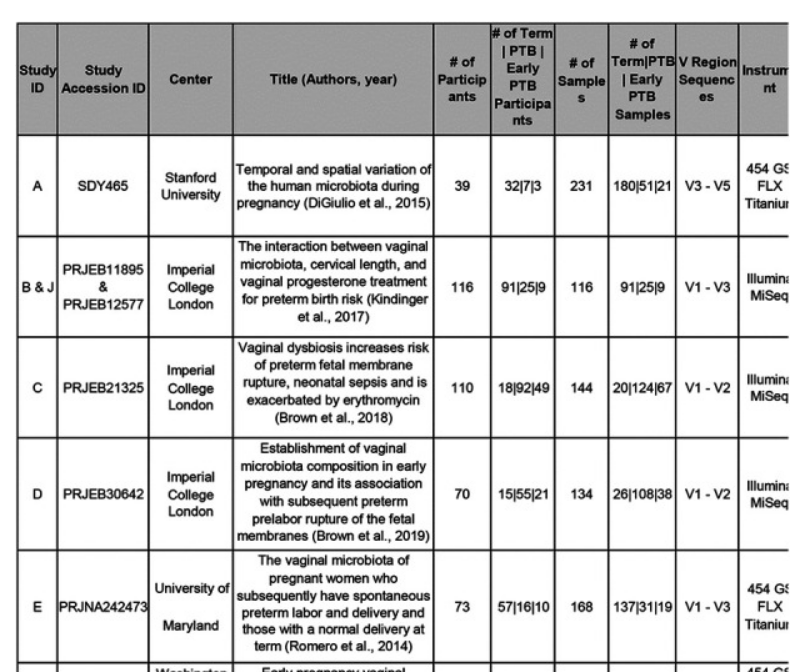
머신러닝 하면 가장 흔히 사용되는 것은 python 의 sklearn 입니다. 만약 더욱 복잡한 모델을 만들고 싶다면 tenserflow 등의 사용도 고려해 봐야겠지만 그 단계에서는 요구하는 컴퓨터의 사양 (GPU) 도 증가하고 학습시키는데 사긴도 상당히 오래 걸립니다. 따라서 초기 단계에서는 sklearn 으로 해당 데이터셋이 머신러닝을 수행하기에 적합한지 알아보는 것도 좋은 방법입니다. 마이크로바이옴 데이터를 기계학습 모델에 적용하고자 하는 시도는 지속적으로 이루어지고 있습니다. 실제 마이크로바이옴 데이터를 분석하는데에 자주 사용되는 QIIME2 에서도 머신 러닝을 수행할 수 있는 플러그인을 제공하고 있습니다. q2-sample-classifer 플러그인은 sklearn 을 기반으로 작성된 머신 러닝..